Spatial scratchpads enable structured 3D reasoning for controllable image generation.
Our method constructs a 3D spatial scratchpad from a text prompt, representing subjects as editable meshes with explicit geometry and spatial relations.
Users or language agents can manipulate this scene — moving, resizing, or reorienting objects — through either text-based or interactive edits.
The updated 3D configuration is re-rendered via a 3D-guided text-to-image pipeline, producing identity-preserving and spatially coherent images that remain faithful to the original prompt.
This demonstrates how 3D reasoning serves as an effective intermediate workspace linking linguistic intent and precise visual synthesis.
Abstract
Recent progress in large language models (LLMs) has shown that reasoning improves when intermediate thoughts are externalized into explicit workspaces, such as chain-of-thought traces or tool-augmented reasoning.
Yet, visual language models (VLMs) lack an analogous mechanism for spatial reasoning, limiting their ability to generate images that accurately reflect geometric relations, object identities, and compositional intent.
We introduce the concept of a spatial scratchpad — a 3D reasoning substrate that bridges linguistic intent and image synthesis.
Given a text prompt, our framework parses subjects and background elements, instantiates them as editable 3D meshes, and employs agentic scene planning for placement, orientation, and viewpoint selection.
The resulting 3D arrangement is rendered back into the image domain with identity-preserving cues, enabling the VLM to generate spatially consistent and visually coherent outputs.
Unlike prior 2D layout-based methods, our approach supports intuitive 3D edits that propagate reliably into final images.
Empirically, it achieves a 32% improvement in text alignment on GenAI-Bench, demonstrating the benefit of explicit 3D reasoning for precise, controllable image generation.
Our results highlight a new paradigm for vision–language models that deliberate not only in language, but also in space.
Method
Overview of a 3D spatial scratchpad.
Given an input prompt P we illustrate how our method uses a 3D space as an underlying representation to generate an image that has superior alignment to the prompt.
Agent 1 is responsible for decomposing the input prompt into subjects and background.
Agent 2 provides 3D bounding boxes for each subject.
We render the scratchpad and subsequently generate an image based on these placements which is then given to agent 3 that adjusts transformations of the meshes.
Finally, agent 4 chooses the best camera viewpoint from a set of proposals to generate the final image.
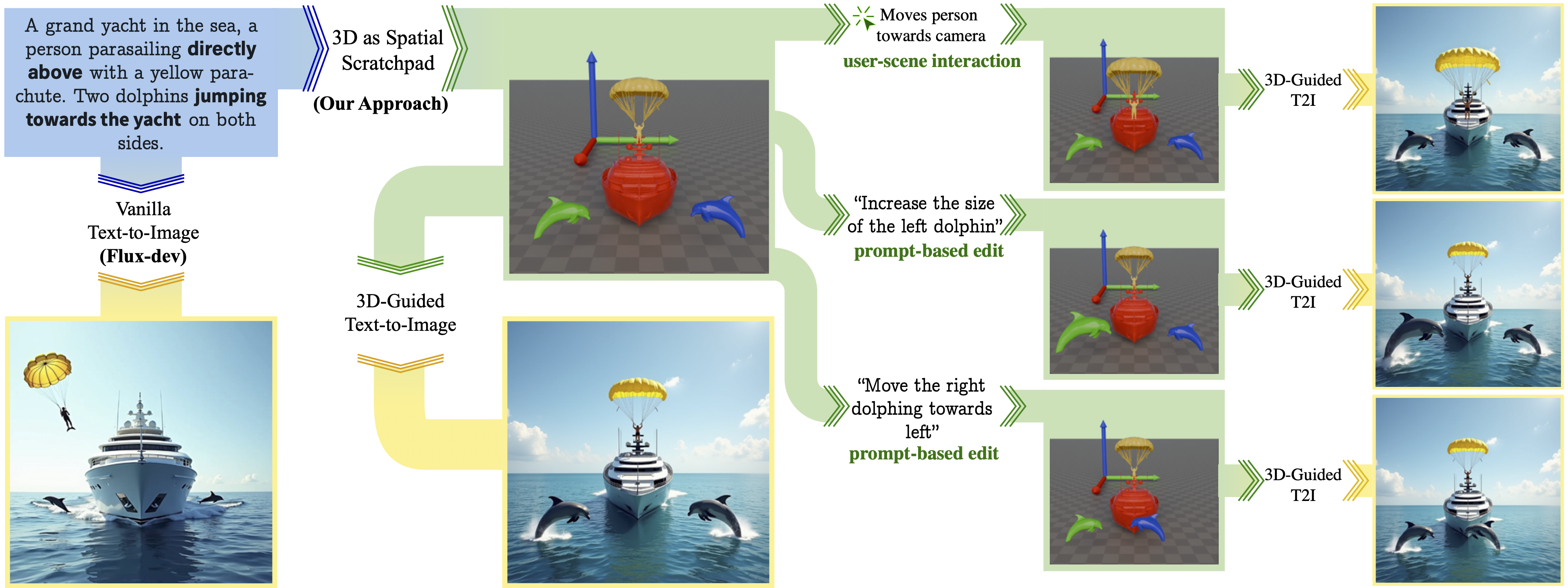
3D as a spatial scratchpad enables consistent image editing.
Given the input prompt, we show the subjects instantiated, the scratchpad created and the subsequent image generated in the first column.
In the succeeding columns, we show how edits made either through a) manual editing, or b) text-based editing to the scratchpad can be consistently reflected on to the final image while conserving identities of subjects and the background.
Each column shows a progressive edit made over the state in the previous column.
Powered by SIGMA-Gen
The identity-preserving, structure-controlled image generation in this work is powered by
SIGMA-Gen — our model for structure- and identity-guided multi-subject
image generation. It renders the 3D scratchpad into a photorealistic image while faithfully
preserving subject identities and obeying the 3D layout.